doc-similarity(根目录)
│
├─SimilarityDjango
├─similarity
│ └─test_doc
│
├─SimilarityApp
│ ├─migrations
│ └─templates
│ └─SimilarityApp
│
├─SimilarityDjango
│
└─static
│ ├─css
│ ├─images
│ └─js
├─upload_data
(1)SimilarityApp:其中__init__.py,admin.py,apps.py,models.py,tests.py,views.py为Django自动生成的文件。根据数据库的结构,修改了models.py中的代码,其中定义了数据库的所有模型。admin.py轻度定制后台管理界面。views.py中定义全部视图函数。||
encryption.py中定义了基于base64的加密函数和解密函数,用于字符串加密和解密。recieve_file.py中定义了本文件定义接收用户上传文件的方法和处理方法(与MySql,redis数据库交互)。
"""
定义接收用户上传文件的方法和处理方法(与MySql,redis数据库交互)
学生上传的源码(压缩包)文件保存在[根目录\upload_data\老师姓名\项目名称\模块名称\学生名称(姓名-账号名)\extends\]路径下
学生上传的doc文件保存在[根目录\upload_data\老师姓名\项目名称\模块名称\学生名称\docs]路径下
老师上传的文件保存在[根目录(和Django项目同级)\upload_data\老师姓名\students_info\]路径下(老师上传的是学生名单文件(Excel格式))
@:param file_object 是request.FILES.get(<input>的name标签)得到的对象,用于获取文件名字和文件数据流
@:param project 是文件所属项目的名称,用于创建项目文件夹
@:param module 是文件所属的项目的某一个模块的名称,用于创建模块文件夹
@:param teacher 是文件所属老师的models模型对象,方便对数据库进行操作,同时用于创建老师的文件夹
@:param student 是文件所属学生的(姓名-账号名),用于创建学生文件夹
@:param is_doc (Boolean type)判断是否是doc类型的文件
接收用户doc文件后分词,然后保存到redis数据库
"""
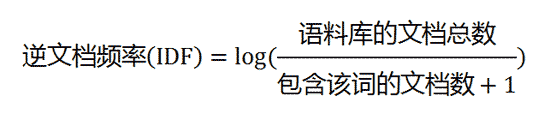
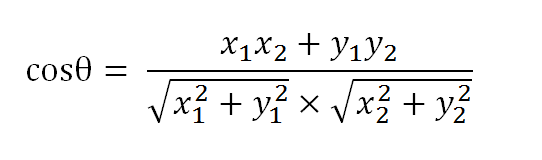
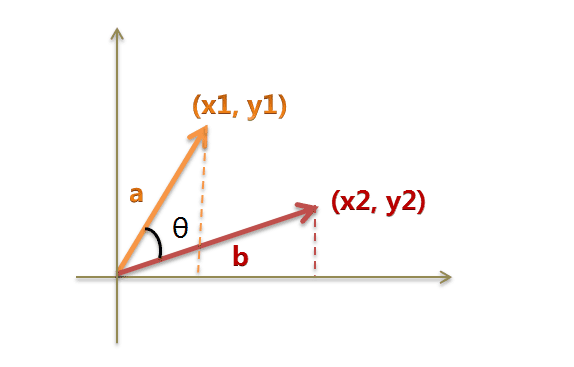
**(1)使用TF-IDF算法,找出两篇文章的关键词 **
(2)每篇文章各取出若干个关键词(比如20个),合并成一个集合,计算每篇文章对于这个集合中的词 的词频(为了避免文章长度的差异,可以使用相对词频)
(3)生成两篇文章各自的词频向量
(4)计算两个向量的余弦相似度,值越大就表示越相似。